|
I'm a Member of Technical Staff at OpenAI, where I work on scaling up reinforcment learning (RL) on large language models (LLMs). My scaling motto is "further, faster, forwards" -- making optimization robust at scale, and then compute efficient, to see how the next 100x in compute can best deliver safe, general intelligence. Before that, I did my PhD at the Gatsby Computational Neuroscience Unit in London, where I was lucky to be co-supervised by Andrew Saxe and Felix Hill. During my PhD, I've had the pleasure of interning at Meta FAIR (with Ari Morcos and then on the Llama 3/3.1 team) and Google DeepMind (on the Grounded Language Agents team). Towards the end of my PhD, I was also lucky to mentor many amazing students. Before my PhD, I did my undergrad and master's at MIT, where I double majored in Computer Science and Neuroscience, and was supervised by Boris Katz and Ila Fiete. I also did a smattering of internships in applied math, computational physics, software engineering, computer vision, and quantitative research on my path to figuring out what I wanted to do. |

|
|
While my most recent work on scaling up RL is [redacted], I've been grateful to contribute key optimization insights (on scaling both further and faster) to frontier model releases such as o3 and GPT-5 Thinking. Before that, my PhD thesis focused on the training dynamics of emergent in-context learning in transformers, motivated by the seminal GPT-3. I also did many side projects on LLMs, ranging from early RL work on multimodal LLMs in multiplayer games to implicit biases imparted by number tokenization. Scroll on to see some selected publications, organized by topic: |
|
| |

|
Aaditya K. Singh, Ted Moskovitz, Sara Dragutinovic, Felix Hill, Stephanie C.Y. Chan*, Andrew M. Saxe* International Conference on Machine Learning (ICML), 2025 arxiv | github | tweet | show bibtex The culmination of our series (1, 2, 3) on ICL dynamics, we answer the question of why ICL emerges, if only to fade away later in training. We find that the asymptotic mechanism, which we term context-constrained in-weights learning (CIWL), is actually a hybrid of in-context learning (ICL) and in-weights learning (IWL). While CIWL competes and eventually "crowds out" ICL, it also shares sub-circuits with ICL which leads to cooperative dynamics as well. We term this phenomenon "strategy coopetition," and propose a minimal mathematical model that reproduces the key dynamics. Informed by this model, we were able to identify a setup where ICL is truly emergent and persistent.
@misc{singh2025strategycoopetitionexplainsemergence, |
|
Yedi Zhang, Aaditya K. Singh, Peter E. Latham*, Andrew M. Saxe* International Conference on Machine Learning (ICML), 2025 arxiv | github | tweet | show bibtex We study the gradient descent dynamics of multi-head linear self-attention trained for in-context linear regression. We show that dynamics can differ across parametrizations, and that the separate parametrization (more like actual transformers) leads to an iterative principal component regression in context with the number of principal components increasing over training time. Overall, we provide a theoretical description of how ICL abilities evolve during gradient descent training of linear attention, revealing abrupt acquisition or progressive improvements depending on how the key and query are parametrized.
@misc{zhang2025trainingdynamicsincontextlearning, |

|
Sara Dragutinovic, Andrew M. Saxe*, Aaditya K. Singh arxiv, 2025 arxiv | github | show bibtex Existing theoretical work, often based on simplifying assumptions, has primarily focused on linear self-attention and continuous regression tasks, finding transformers can learn in-context by gradient descent. Given that transformers are typically trained on discrete and complex tasks, we bridge the gap from this existing work to the setting of classification, with non-linear (importantly, softmax) activation. We find that transformers still learn to do gradient descent in-context, though on functionals in the kernel feature space and with a context-adaptive learning rate in the case of softmax transformer.
@misc{dragutinovic2025softmaxgeqlineartransformers, |

|
Jin Hwa Lee, Andrew Kyle Lampinen, Aaditya K. Singh*, Andrew M. Saxe* arxiv, 2025 arxiv | show bibtex We investigate how presenting a compositional subtask curriculum in context may alter the computations a transformer learns. Models trained with a subtask curriculum can perform zero-shot inference on unseen compositional tasks and are more robust given the same context length. We study how the task and subtasks are represented across the two training regimes. We find that the models employ diverse strategies modulated by the specific curriculum design.
@misc{lee2025distinctcomputationsemergecompositional, |
|
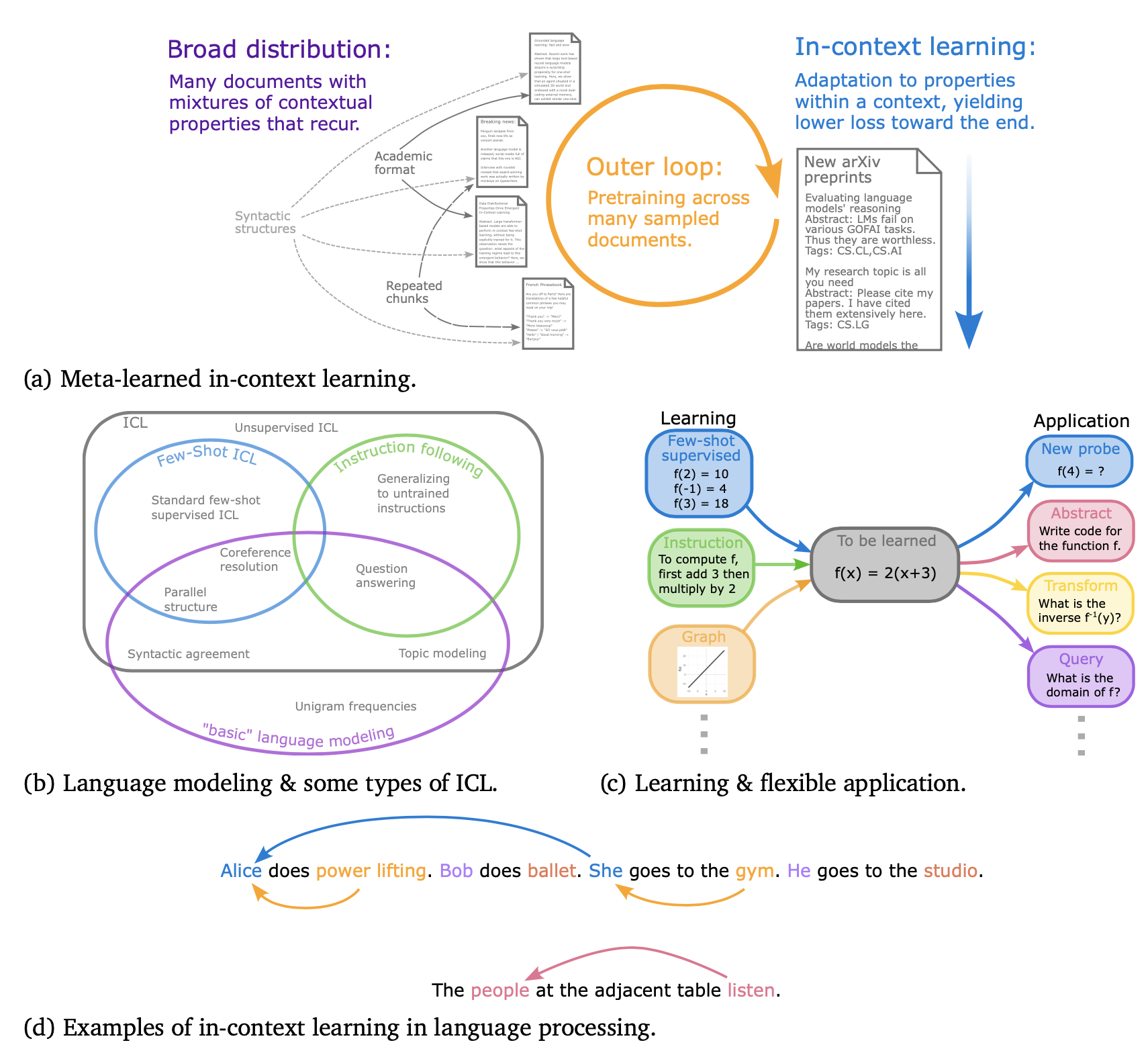
Andrew Kyle Lampinen, Stephanie C.Y. Chan, Aaditya K. Singh, Murray Shanahan arxiv, 2024 arxiv | tweet | show bibtex We provide a perspective that situates supervised few-shot learning in LLMs within a much broader spectrum of meta-learned in-context learning. We suggest that any distribution of sequences in which context non-trivially decreases loss on subsequent predictions can be interpreted as eliciting a kind of in-context learning. This perspective helps to unify the broad set of in-context abilities that language models exhibit -- such as adapting to tasks from instructions or role play, or extrapolating time series. This perspective also sheds light on potential roots of in-context learning in lower-level processing of linguistic dependencies (e.g. coreference or parallel structures). Finally, taking this perspective highlights the importance of generalization, which we suggest can be studied along several dimensions: not only the ability to learn something novel, but also flexibility in learning from different presentations, and in applying what is learned.
@misc{lampinen2025broaderspectrumincontextlearning, |
|
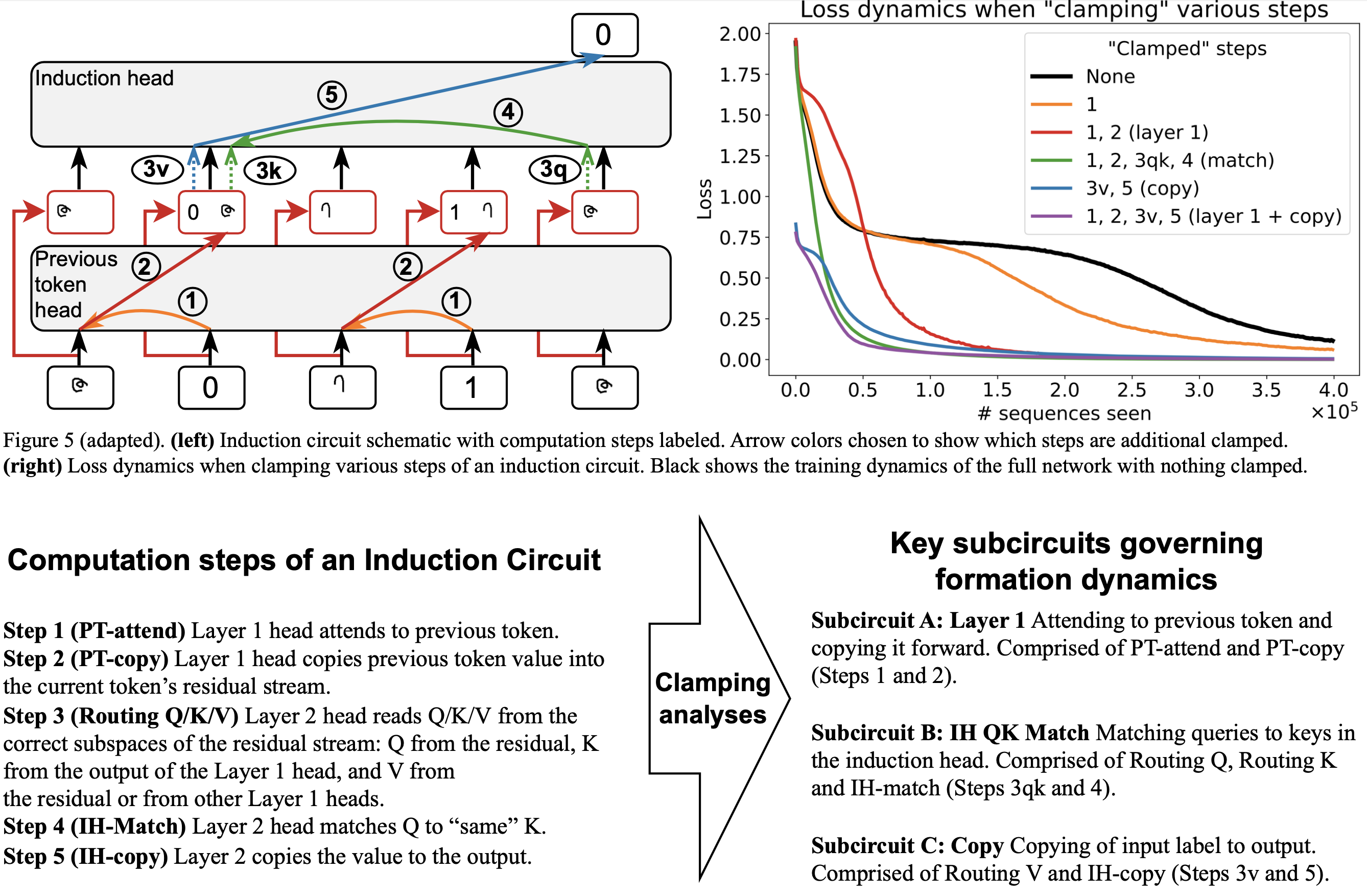
Aaditya K. Singh, Ted Moskovitz, Felix Hill, Stephanie C.Y. Chan*, Andrew M. Saxe* International Conference on Machine Learning (ICML), 2024 arxiv | github | tweet | show bibtex Induction heads are thought to be responsible for much of in-context learning. We take inspiration from optogenetics in neuroscience to introduce a framework for measuring and manipulating activations in a deep network throughout training. We introduce the method of clamping to better understand what gives rise to the phase change characteristic of induction circuit formation, finding that the interaction between three smoothly evolving sub-circuits yields this sudden drop in the loss.
@misc{singh2024needsrightinductionhead, |
|
|
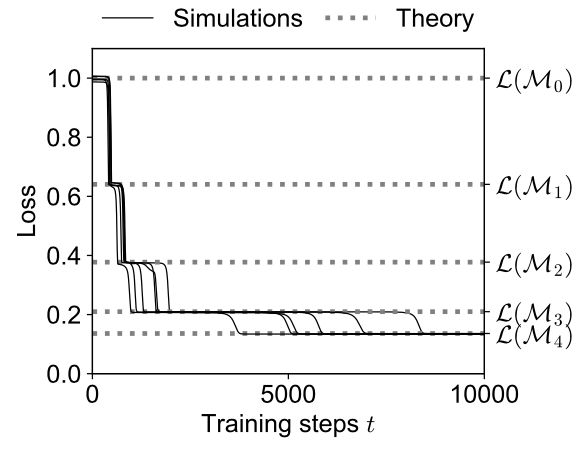
Aaditya K. Singh*, Stephanie C.Y. Chan*, Ted Moskovitz, Erin Grant, Andrew M. Saxe**, Felix Hill** Neural Information Processing Systems (NeurIPS), 2023 arxiv | neurips | github | tweet | show bibtex We train transformers on synthetic data designed so that both in-context learning (ICL) and in-weights learning (IWL) strategies can lead to correct predictions. We find that ICL is often transient, meaning it first emerges, then disappears and gives way to IWL, all while the training loss decreases, indicating an asymptotic preference for IWL. We find that L2 regularization may offer a path to more persistent ICL that removes the need for early stopping based on ICL-style validation tasks. Finally, we present initial evidence that ICL transience may be caused by competition between ICL and IWL circuits.
@inproceedings{singh2023transience, Reproduced by this recent paper in naturalistic settings, and this other paper in a different synthetic setting. |
|
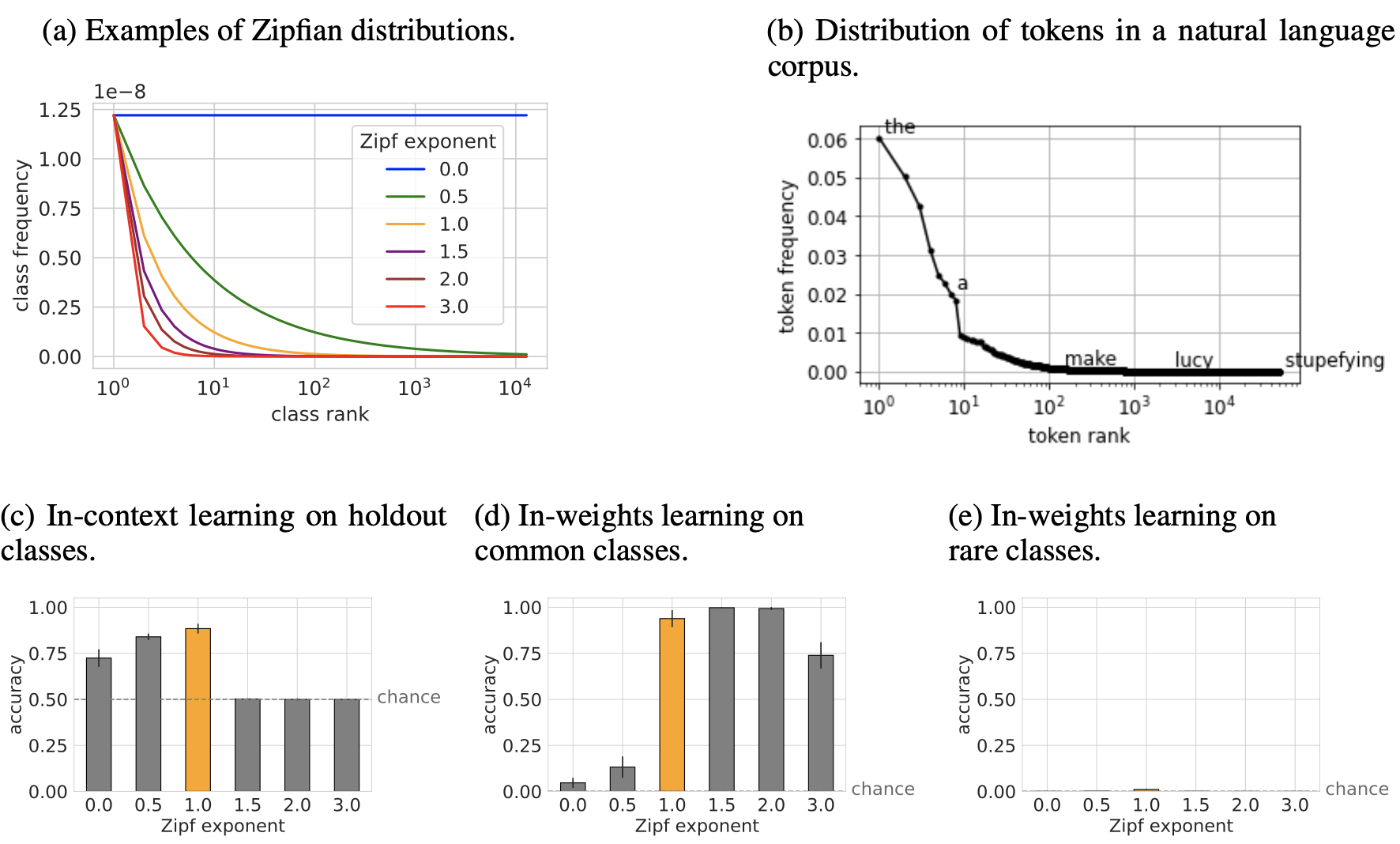
Stephanie C.Y. Chan, Adam Santoro, Andrew Kyle Lampinen, Jane X. Wang, Aaditya K. Singh, Pierre H. Richemond, Jay McClelland, Felix Hill Neural Information Processing Systems (NeurIPS), 2022 arxiv | neurips | github | tweet | show bibtex Large transformer-based models are able to perform in-context few-shot learning, without being explicitly trained for it. We find that in-context learning (ICL) emerges when the training data exhibits particular distributional properties such as burstiness (items appear in clusters rather than being uniformly distributed over time) and having large numbers of rarely occurring classes. We found that in-context learning typically trades off against more conventional weight-based learning, but that the two modes of learning could co-exist in a single model when it was trained on data following a skewed Zipfian distribution (a common property of naturalistic data, including language).
@inproceedings{chan2022icldata, Our insights were used by this recent paper to elicit ICL in RL settings. |
|
| |
|
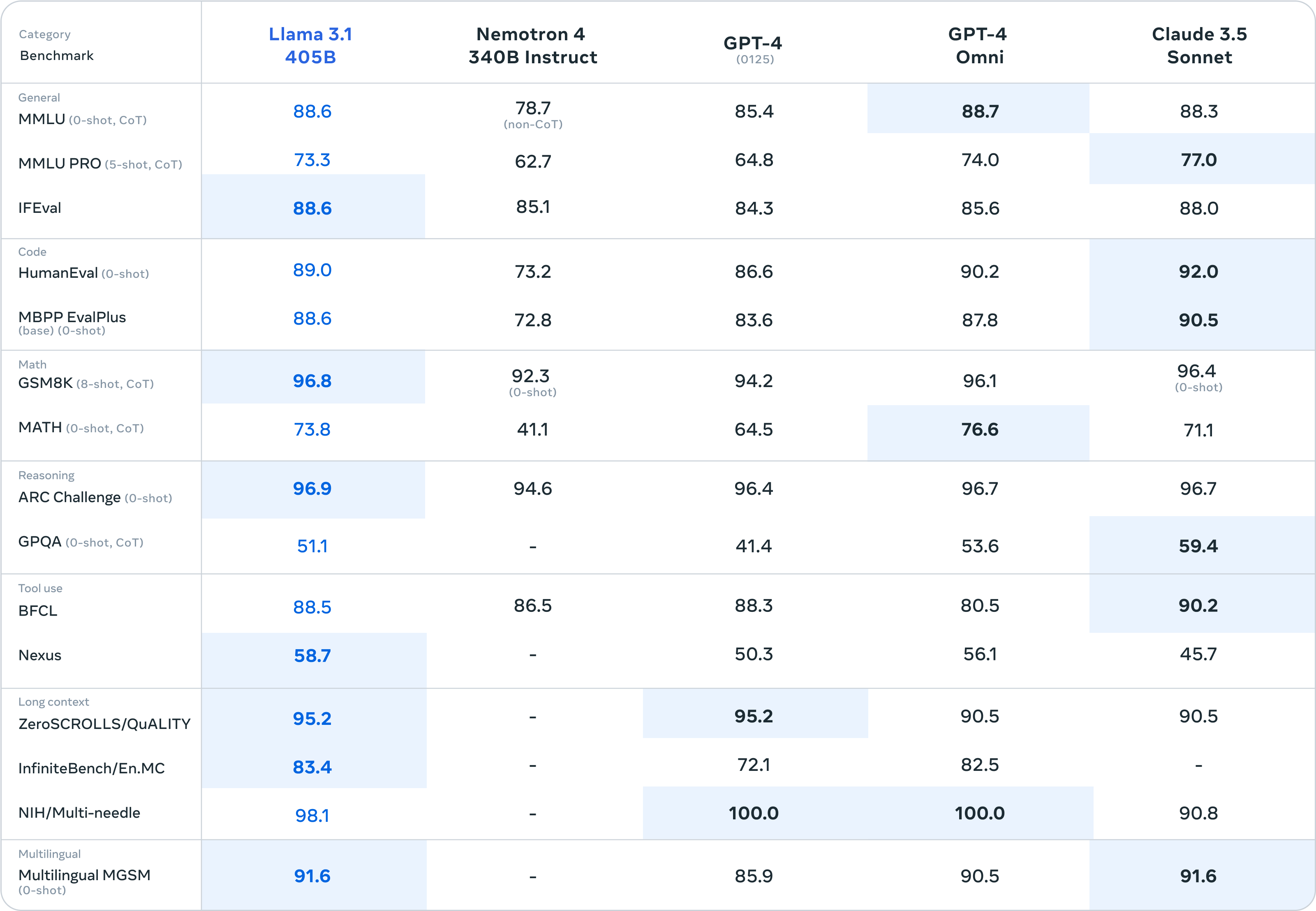
Llama team, AI@Meta, Contributors: Aaditya K. Singh, ... arxiv | github | tweet | show bibtex Llama 3 is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens.
@misc{llama3herdmodels, My contributions: Math pretraining data (S3.1.1), Scaling laws (S3.2.1), and Evals (S5). |
|
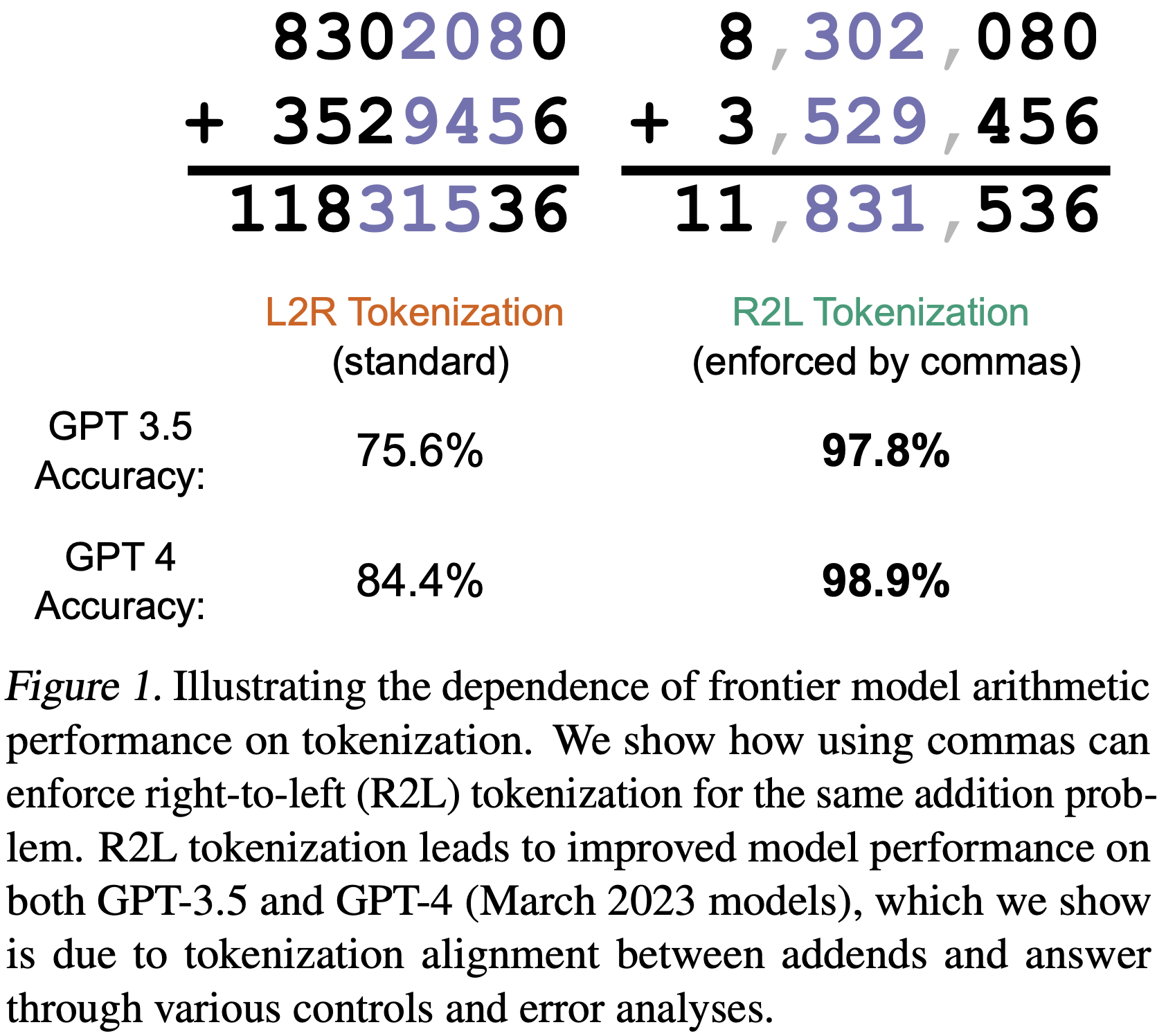
Aaditya K. Singh, DJ Strouse arxiv, 2024 arxiv | github | tweet | show bibtex Through a series of carefully controlled, inference-time experiments, we find evidence of strong (scale-dependent) number tokenization-induced inductive biases in numerical reasoning in frontier LLMs. Specifically, we demonstrate that GPT-3.5 and GPT-4 models show largely improved performance when using right-to-left (as opposed to default left-to-right) number tokenization. Furthermore, we find that model errors when using standard left-to-right tokenization follow stereotyped error patterns, suggesting that model computations are systematic rather than approximate. These effects are weaker in larger models (GPT-4) yet stronger in newer, smaller models (GPT 4 Turbo).
@misc{singh2024tokenization, Reproduced by this recent blog post in newer models (e.g., Llama 3). Claude 3, released after our work and with SOTA math capabilities, also notably uses R2L tokenization. |
|
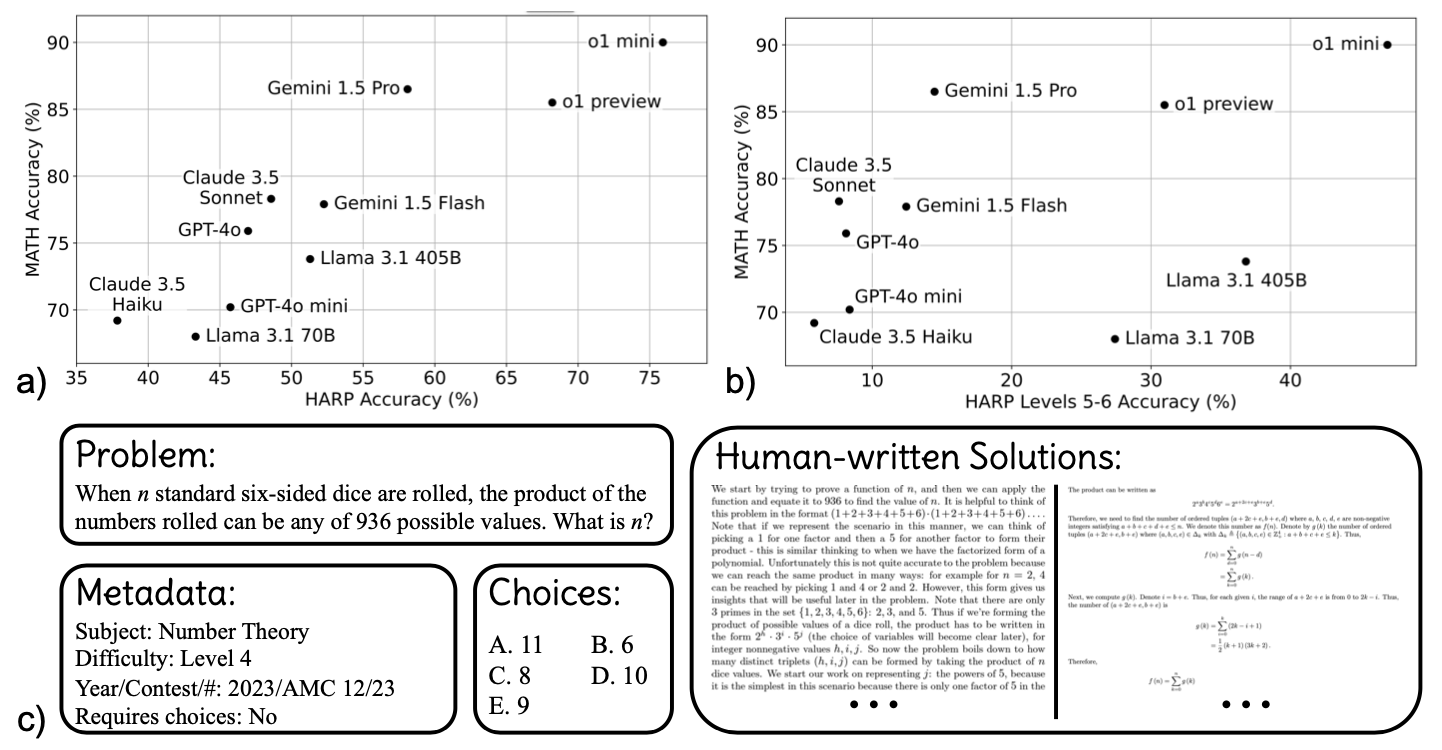
Albert S. Yue, Lovish Madaan, Ted Moskovitz, DJ Strouse, Aaditya K. Singh arxiv, 2024 arxiv | github | tweet | show bibtex We introduce HARP, Human Annotated Reasoning Problems (for Math), consisting of 5,409 problems from the US national math competitions (A(J)HSME, AMC, AIME, USA(J)MO). Of these, 4,780 have answers that are automatically check-able (with libraries such as SymPy). Our dataset also features multiple choices (for 4,110 problems) and an average of two human-written, ground-truth solutions per problem, offering new avenues of research that we explore briefly. We report evaluations for many frontier models and share some interesting analyses, such as demonstrating that frontier models across families intrinsically scale their inference-time compute for more difficult problems.
@misc{yue2024harpchallenginghumanannotatedmath, |
|
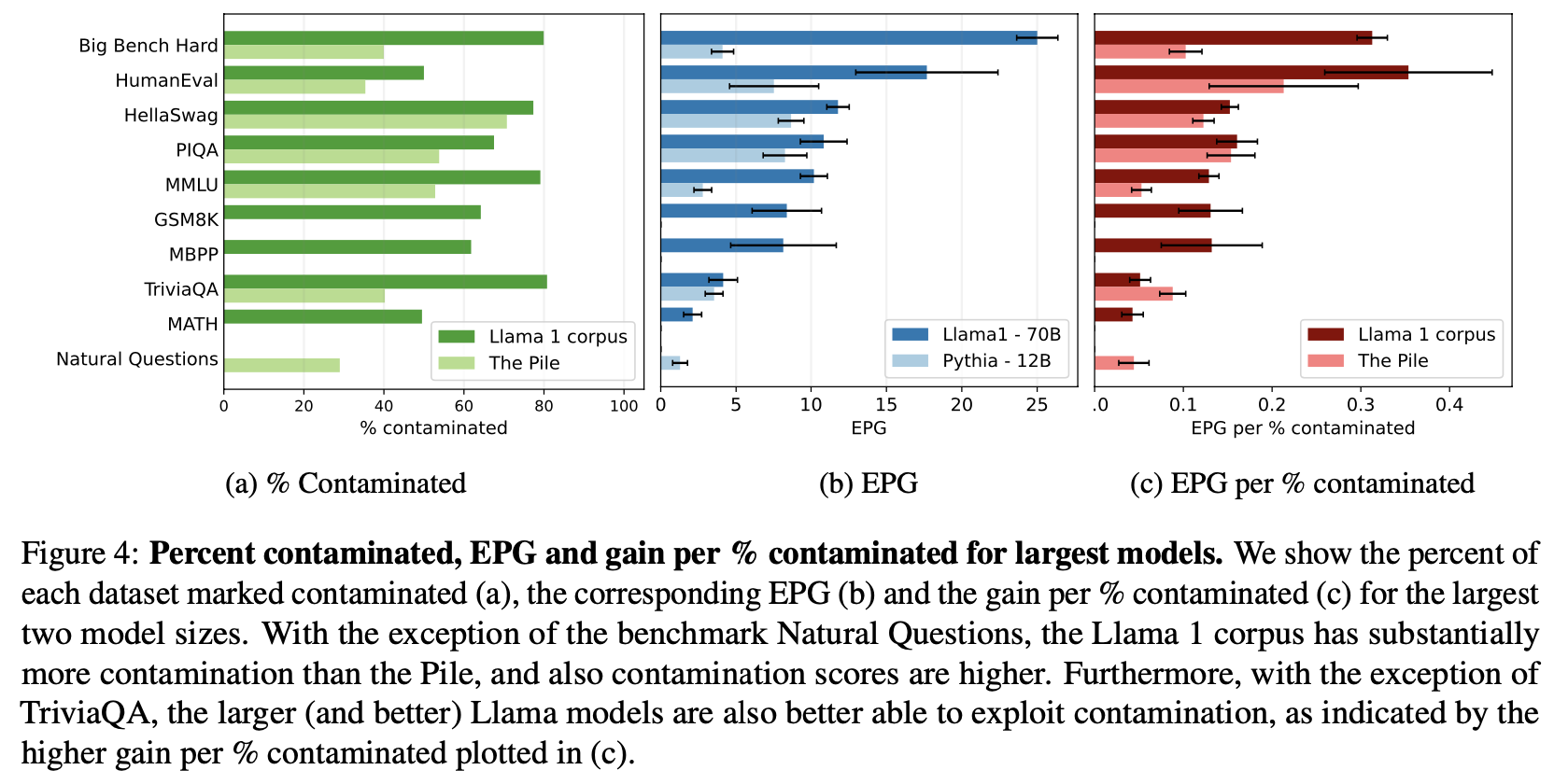
Aaditya K. Singh*, Muhammed Yusuf Kocyigit*, Andrew Poulton, David Esiobu, Maria Lomeli, Gergely Szilvasy, Dieuwke Hupkes In submission, 2024 arxiv | show bibtex Evaluation data contamination is defined as the presence of benchmark samples in pretraining data, and the subsequent effects on performance. While easily understood intuitively, it is surprisingly difficult to define precisely which samples should be considered contaminated and, consequently, how it impacts benchmark scores. We propose that these questions should be addressed together and that contamination metrics can be assessed based on whether models benefit from the examples they mark contaminated. We propose a novel analysis method called ConTAM, and show with a large scale survey that our method can be used to better understand evaluation data contamination and its effects. We find that contamination effects may be more prevalent than reported in recent LLM releases and can be scale-dependent. We also find that considering only the longest contaminated substring provides a better signal than other n-gram based metrics.
@misc{singh2024evaluationdatacontaminationllms, |
|
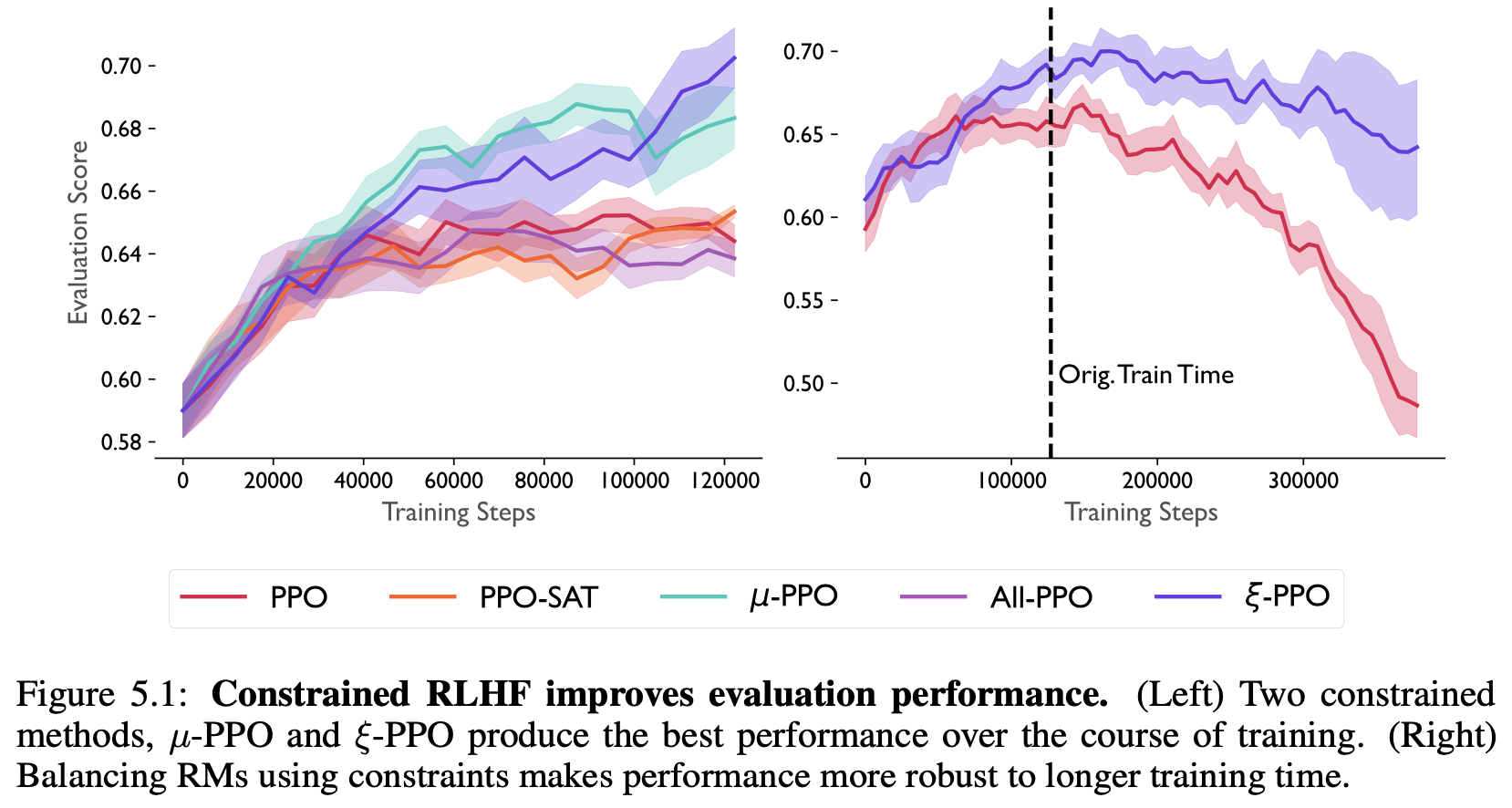
Ted Moskovitz, Aaditya K. Singh, DJ Strouse, Tuomas Sandholm, Ruslan Salakhutdinov, Anca D. Dragan, Stephen McAleer International Conference on Learning Representations, 2024 arxiv | openreview | tweet | show bibtex Optimizing large language models to align with human preferences via reinforcement learning from human feedback can offer suffer from overoptimization. Furthermore, human preferences are often multi-faceted, requiring many sub-components. In this work, we study overoptimization in composite RMs showing that correlation between component RMs has a significant effect. We then introduce an approach to circumvent this issue using constrained reinforcement learning as a means of preventing the agent from exceeding each RM's threshold of usefulness. Our method addresses the problem of weighting component RMs by learning dynamic weights, naturally expressed by Lagrange multipliers. As a result, each RM stays within the range at which it is an effective proxy, improving evaluation performance.
@misc{moskovitz2023confrontingrewardmodeloveroptimization, |
|
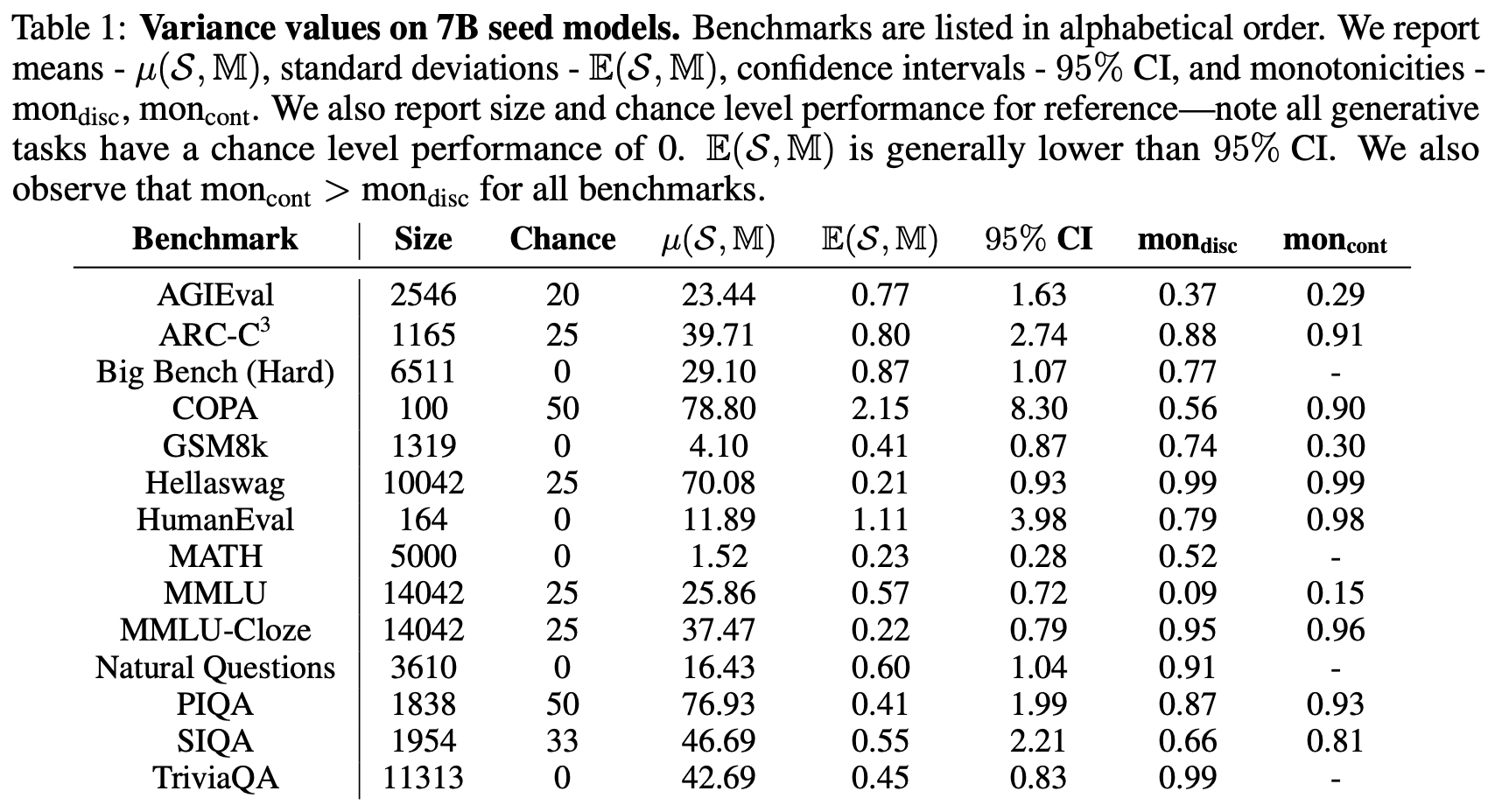
Lovish Madaan, Aaditya K. Singh, Rylan Schaeffer, Andrew Poulton, Sanmi Koyejo, Pontus Stenetorp, Sharan Narang, Dieuwke Hupkes In submission, 2024 arxiv | tweet | show bibtex We quantify variance in evaluation benchmarks through a range of metrics, including difference in performance across ten 7B 210B token runs with different initializations. We find that continuous metrics often show less variance (higher signal-to-noise), suggesting they may be more useful when doing pretraining ablations, especially at smaller compute scales. Furthermore, we find that methods from human testing (e.g., item analysis or item response theory) are not effective at reducing variance.
@misc{madaan2024variance, |

|
Aaditya K. Singh, Yu Yang, Kushal Tirumala, Mostafa Elhoushi, Ari S. Morcos Data-centric Machine Learning Research Workshop @ ICML, 2024 arxiv | tweet | show bibtex Longer files are often conflated with "higher quality" data. This breaks down for code! The longest Python files in the public Stack dataset are often nonsensical, yet make up a disproportionate amount of tokens (2% of files make up 20% of tokens). We provide qualitative and quantitative evidence for this, ending with the causal experiment: pruning these files leads to modest improvements in efficiency and/or performance at small compute scales. As compute is scaled up, benefits diminish, as seen in related work.
@misc{singh2024brevity, |
|
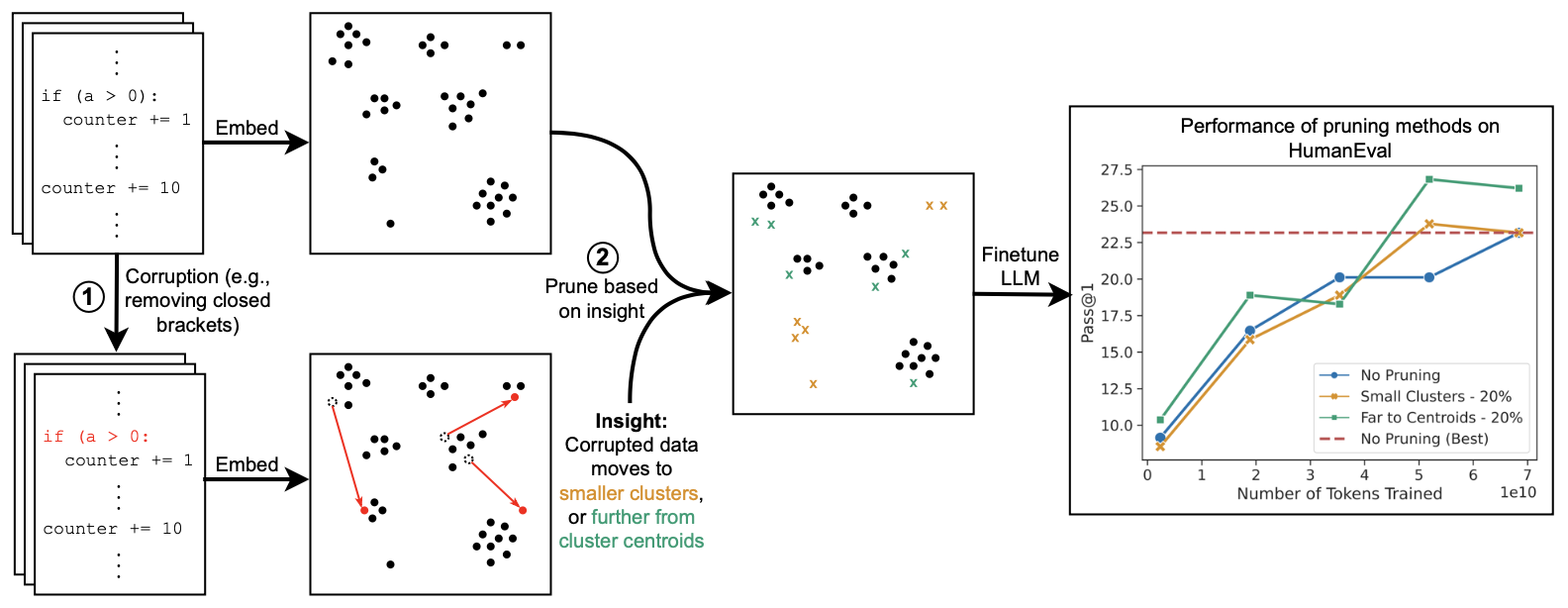
Yu Yang, Aaditya K. Singh, Mostafa Elhoushi, Anas Mahmoud, Kushal Tirumala, Fabian Gloeckle, Baptiste Rozière, Carole-Jean Wu, Ari S. Morcos, Newsha Ardalani Efficient Natural Language and Speech Processing Workshop @ NeurIPS, 2023 arxiv | tweet | show bibtex Code datasets, often collected from diverse and uncontrolled sources such as GitHub, potentially suffer from quality issues, thereby affecting the performance and training efficiency of Large Language Models (LLMs) optimized for code generation. First, we explore features of "low-quality" code in embedding space, through the use of synthetic corruptions. Armed with this knowledge, we devise novel pruning metrics that operate in embedding space to identify and remove low-quality entries in the Stack dataset. We demonstrate the benefits of this synthetic corruption informed pruning (SCIP) approach on the well-established HumanEval and MBPP benchmarks, outperforming existing embedding-based methods.
@misc{yang2023scip, |
|
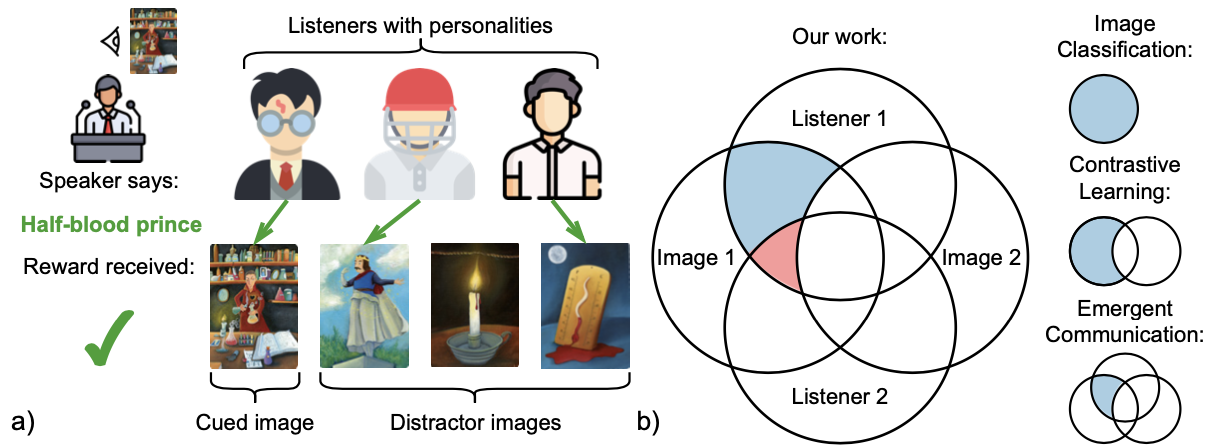
Aaditya K. Singh, David Ding, Andrew M. Saxe, Felix Hill, Andrew Kyle Lampinen European chapter of the Association for Computational Linguistics (EACL), 2023 arxiv | ACL Anthology | tweet | show bibtex Effective communication requires adapting to the idiosyncrasies of each communicative context--such as the common ground shared with each partner. Humans demonstrate this ability to specialize to their audience in many contexts, such as the popular game Dixit. We take inspiration from Dixit to formulate a multi-agent image reference game where a (trained) speaker model is rewarded for describing a target image such that one (pretrained) listener model can correctly identify it among distractors, but another listener cannot. To adapt, the speaker must exploit differences in the knowledge it shares with the different listeners. We show that finetuning an attention-based adapter between a CLIP vision encoder and a large language model in this contrastive, multi-agent setting gives rise to context-dependent natural language specialization from rewards only, without direct supervision.
@inproceedings{singh-etal-2023-know, Our Perceiver IO-inspired cross-attention adapter was used by concurrent work and shown to be generally useful for image captioning. |
|
| |
|
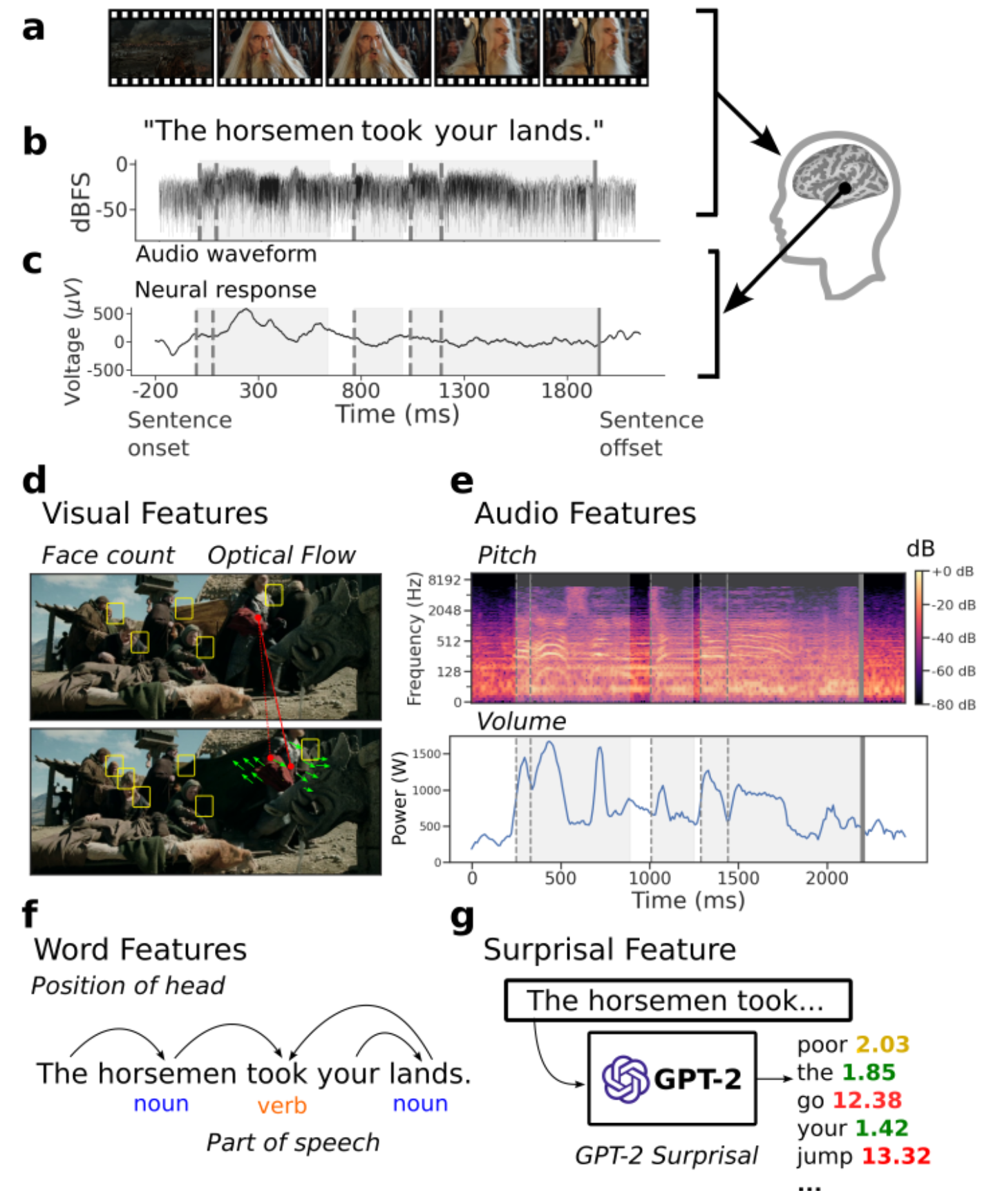
Christopher Wang*, Adam Yaari*, Aaditya K. Singh, Vighnesh Subramaniam, Dana Rosenfarb, Jan DeWitt, Pranav Misra, Joseph R. Madsen, Scellig Stone, Gabriel Kreiman, Boris Katz, Ignacio Cases, Andrei Barbu, Neural Information Processing Systems (NeurIPS), 2024 project page | neurips | pdf | show bibtex We present the Brain Treebank, a large-scale dataset of electrophysiological neural responses, recorded from intracranial probes while 10 subjects watched one or more Hollywood movies. Subjects watched on average 2.6 Hollywood movies, for an average viewing time of 4.3 hours, and a total of 43 hours. The audio track for each movie was transcribed with manual corrections. Word onsets were manually annotated on spectrograms of the audio track for each movie. Each transcript was automatically parsed and manually corrected into the universal dependencies (UD) formalism, assigning a part of speech to every word and a dependency parse to every sentence. In total, subjects heard over 38,000 sentences (223,000 words), while they had on average 168 electrodes implanted. This is the largest dataset of intracranial recordings featuring grounded naturalistic language, one of the largest English UD treebanks in general, and one of only a few UD treebanks aligned to multimodal features. We hope that this dataset serves as a bridge between linguistic concepts, perception, and their neural representations. To that end, we present an analysis of which electrodes are sensitive to language features while also mapping out a rough time course of language processing across these electrodes.
@inproceedings{wang2024braintreebank, |
| |